This blog post is part of a series describing my ongoing analysis of the Kaggle Horses For Courses data set using Azure Data Lake Analytics with U-SQL and Azure Notebooks with F#. This is part 1.
- Horses For Courses data set analysis with Azure Data Lake and U-SQL (this blog post)
- Horses For Courses barrier analysis with Azure Notebooks
- Kaggle Horses for Courses age analysis with Azure Notebooks
- Kaggle Horses for Courses analysis of last five starts with Azure Notebooks
The data set
Kaggle is a data science community that hosts numerous data sets and data science competitions. One of these data sets is 'Horses For Courses'. It's a (relatively) small set of anonymized horse racing data. It tells you which horses participated in a race, how old they were, from what barrier they started, what the weather was like at the time of the race, betting odds and a lot more. The official goal is to predict the finishing position of a horse in a race. The real goal is of course to beat the odds and win a lot of money betting on horse races via a machine learning model :)
Azure Data Lake
The data set, unzipped, is a little over 100MB, nothing you can't handle on a laptop. But since data sets aren't usually this small, I was looking for a cloud solution that allows analysis of large data sets, just to get some experience with that.
As it happens, Azure Data Lake provides storage for (really) large data sets and Azure Data Lake Analytics provides analytics capabilities through a SQL-dialect called U-SQL. Data Lake Store is built on top of Apache Hadoop YARN and Data Lake Analytics uses MapReduce-style execution of workloads. It's a pay-as-you-go model so if you don't run large jobs or store a lot of data, it costs you next to nothing.
Preparing the data
The data set can be downloaded as a zip file from Kaggle. I unzipped the file and uploaded the contents to an Azure Blob Storage container:
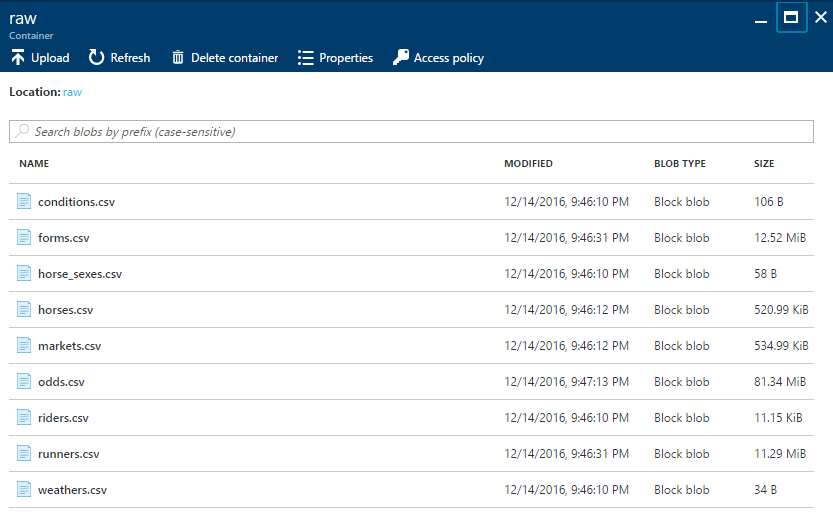
Why Azure Blob Storage and not Azure Data Lake itself? Well, I'd like to do some data analysis using Azure Notebooks with F# and blob storage provides easy access to blobs without authentication (haven't found that for Data Lake yet).
Data Lake tables
Now that we have the csv files in place, we first create Azure Data Lake tables from these files. This isn't strictly necessary because Data Lake uses so-called schema-on-read so we could just extract data from the csv files and analyze this directly. However, when you need to extract data multiple times from the same set of csv files, table definitions are really helpful.
Our first target for analysis is runners.csv. It has a row for every horse in every race and includes finishing position (the field we want to predict with our money-making ML model). BTW: all source code in this post and the ones that follow is also available on Github. Let's create a table for the runners.csv file:
CREATE TYPE IF NOT EXISTS RunnersType
AS TABLE (Id int, Collected DateTime, MarketId int, Position int?, ...,
HorseId int, ..., Barrier int, ...);
DROP TABLE IF EXISTS Runners;
DROP FUNCTION IF EXISTS RunnersTVF;
CREATE FUNCTION RunnersTVF()
RETURNS @runners RunnersType
AS
BEGIN
@runners =
EXTRACT Id int,
Collected DateTime,
MarketId int,
Position int?,
...,
HorseId int,
...,
Barrier int,
...
FROM "wasb://raw@rwwildenml.blob.core.windows.net/runners.csv"
USING Extractors.Csv(skipFirstNRows : 1);
END;
CREATE TABLE Runners
(
INDEX RunnersIdx CLUSTERED(Id ASC)
DISTRIBUTED BY HASH(HorseId)
)
AS RunnersTVF();
A lot of things happen here. Let's get into the details one by one:
- First of all, this is not the only way to create a table. You can also create a table directly from an
EXTRACTstatement. It's a little more work like this but I like that you explicitly define a table type. - The column data types you see are actual C# types. You can use any C# type in a U-SQL script (but only a subset can be used for column types).
- The
EXTRACTstatement reads a CSV file from a blob storage account via the url:wasb://raw@rwwildenml.blob.core.windows.net/runners.csvwhere:wasbstands for Windows Azure Storage Blob,rawis the name of the blob storage container where the files live,rwwildenml.blob.core.windows.netis the name of my storage account andrunners.csvis the name of the file.
- Before you can read from blob storage in Data Lake Analytics, you have to add the blob storage account as a data source.
- I skipped some columns for readability, indicated by the
...s, the actual file has 40 columns. - A table needs an index and a partitioning/distribution scheme. An obvious column to partition the data on isn't really available so I specified only a distribution.
When we run the above script an actual table is created and stored inside Azure Data Lake. You can join this table to other tables, you can group, you can use aggregates, etc. And while I have a very small table, the same principles apply to giga- or tera-byte tables. In that case you would have to give some more careful consideration to partitioning.
Visual Studio U-SQL projects
A next logical question would be: how do I run this script? The two easiest ways are: directly from the Azure portal or from within Visual Studio. I used the latter and installed Visual Studio 2017. A simple File → New Project gives you the option to create a new U-SQL Project1.
Of course, you also need an Azure Data Lake Store and Azure Data Lake Analytics resource in Azure. Both can simply be created from the Azure Portal.
From within Visual Studio, you can actually connect to your Data Lake Analytics resource(s) in Azure using Server Explorer:
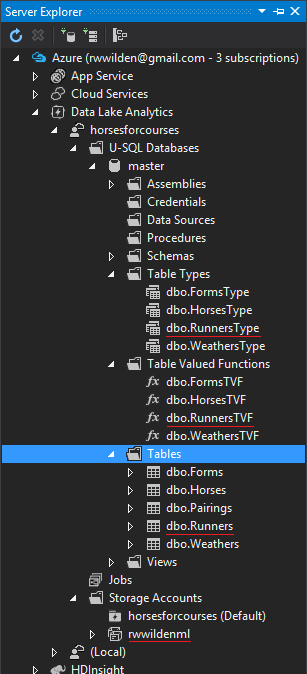
I highlighted the resources we created with the script above and the linked blob storage account (rwwildenml).
Analysis
With all the plumbing out of the way, we can start analyzing the data. Remember, our goal is to predict finishing positions of horses in a race. This is essentially a ranking problem. Suppose we have four horses in a race: A, B, C and D and let's assume they finish in alphabetical order. We can then generate pairs for each horse combination and label them as follows:
1. A B won
2. A C won
3. A D won
4. B A lost
5. B C won
6. B D won
7. C A lost
8. C B lost
9. C D won
10. D A lost
11. D B lost
12. D C lost
On row 1, horse A finished before horse B so we label this as won. On row 8, horse C finished after horse B so this is labeled lost. We can do this for every horse race in the runners.csv file.
The following U-SQL script creates a table called Pairings that contains each pair of horses per race, whether the first horse in the pair won and what the distance was between finishing positions.
DROP TABLE IF EXISTS Pairings;
CREATE TABLE Pairings
(
INDEX PairingsIdx CLUSTERED(HorseId0 ASC, HorseId1 ASC)
PARTITIONED BY HASH (HorseId0, HorseId1)
)
AS
SELECT
r0.MarketId,
r0.HorseId AS HorseId0,
r1.HorseId AS HorseId1,
HorsesForCourses.Functions.Won(
r0.Position.Value, r1.Position.Value) AS Won,
HorsesForCourses.Functions.Distance(
r0.Position.Value, r1.Position.Value) AS Distance
FROM master.dbo.Runners AS r0
JOIN master.dbo.Runners AS r1 ON r0.MarketId == r1.MarketId
WHERE r0.HorseId != r1.HorseId
AND r0.Position.HasValue
AND r1.Position.HasValue;
We simply join the Runners table against itself where both race ids (market ids) are equal. Horses are not compared against themselves and both positions must have a value.
You may wonder, what are HorsesForCourses.Functions.Won and HorsesForCourses.Functions.Distance? Well, you can actually use C# user defined functions (and lots more) from U-SQL. Won and Distance are two very simple functions that return a bool and an int, respectively.
When we run this script, we get a table with the following columns:
MarketId: the id of the race the horses participated inHorseId0: a horse in the raceHorseId1: another horse in the same raceWon: whether the first horse (HorseId0) won or lostDistance: the difference between horse positions
Barriers
Using the Pairings table we just created, we can derive other data. The first data set we're going to create has the following columns:
Barrier0: what was the starting barrier for the first horseBarrier1: what was the starting barrier for the second horseWon: which horse won
When we have this set, we can try and determine if barrier has an effect on a horse's chances of winning a race. The analysis of this data set is the topic of the next post so we'll finish here with a script that generates the CSV file in blob storage:
@barriers =
SELECT r0.Barrier AS Barrier0,
r1.Barrier AS Barrier1,
p.Won
FROM master.dbo.Pairings AS p
JOIN master.dbo.Runners AS r0 ON p.HorseId0 == r0.HorseId AND
p.MarketId == r0.MarketId
JOIN master.dbo.Runners AS r1 ON p.HorseId1 == r1.HorseId AND
p.MarketId == r1.MarketId;
OUTPUT @barriers
TO "wasb://output@rwwildenml.blob.core.windows.net/barriers.csv"
USING Outputters.Csv();
First we generate a new data set called @barriers by joining our Pairings table twice to Runners (for horse 0 and horse 1). Next we output this data set to a CSV file in blob storage. We now have a file that contains, for every race, the barriers for each horse pair in each race and whether this resulted in a win or a los. If we take one row, for example:
3,7,True
This indicates that in a particular race, the horse starting from barrier 3 has beaten the horse starting from barrier 7.
One final screenshot from Visual Studio may be interesting and that is the job graph that describes what happened when we ran the last script:
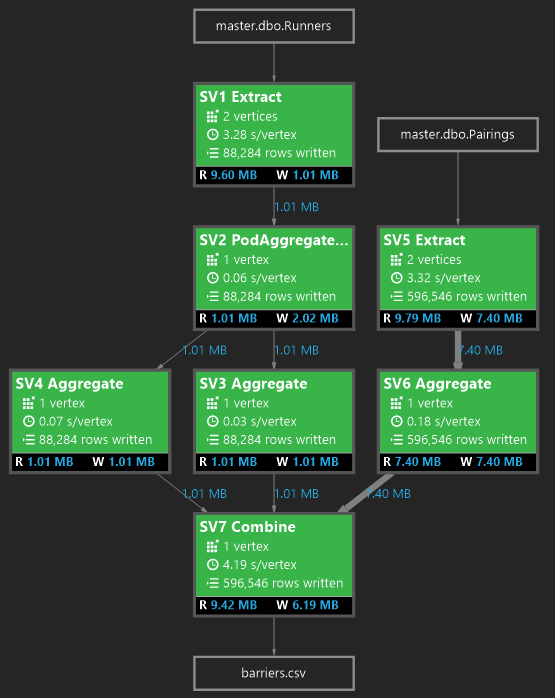
As you can see, there were two inputs: master.dbo.Runners and master.dbo.Pairings. Each block represents an operation on data. The final block generates the barriers.csv file with 596546 rows.
Footnotes
- Only if Visual Studio 2017 was installed with the Data storage and processing workload.